
Skills & Tools Used:
✔ Python (TensorFlow/Keras, XGBoost, Pandas, NumPy, Scikit-learn)
✔ Deep Learning (DNN Feature Engineering)
✔ Machine Learning (XGBoost Classification, SMOTE for Imbalanced Data)
✔ Model Evaluation (Confusion Matrix, Accuracy, Precision, Recall, F1-Score)
✔ Hyperparameter Tuning & Optimization
Project Overview
This project evaluates the performance of a hybrid Deep Neural Network (DNN) and XGBoost model for credit scoring classification. By combining DNN for feature extraction and XGBoost for classification, we aim to enhance model accuracy and robustness compared to single-model approaches.
Key Findings
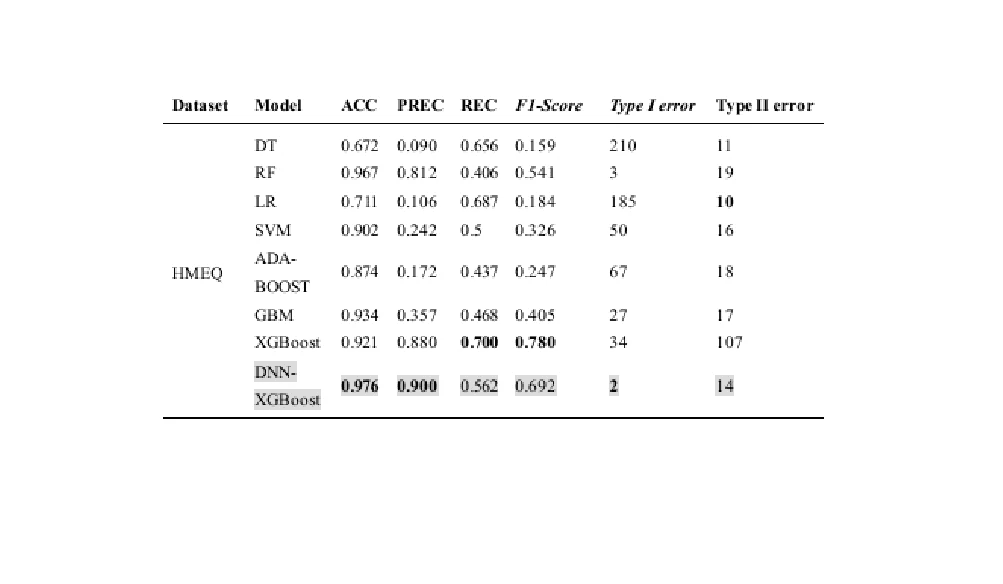
DNN-XGBoost outperformed traditional models, achieving the highest accuracy across all datasets.
The best accuracy (0.976) was obtained on the HMEQ dataset, with strong performance across German and Japanese datasets as well.
The model performed particularly well in accuracy, precision, and Type I error reduction across multiple datasets.
Model Development Process
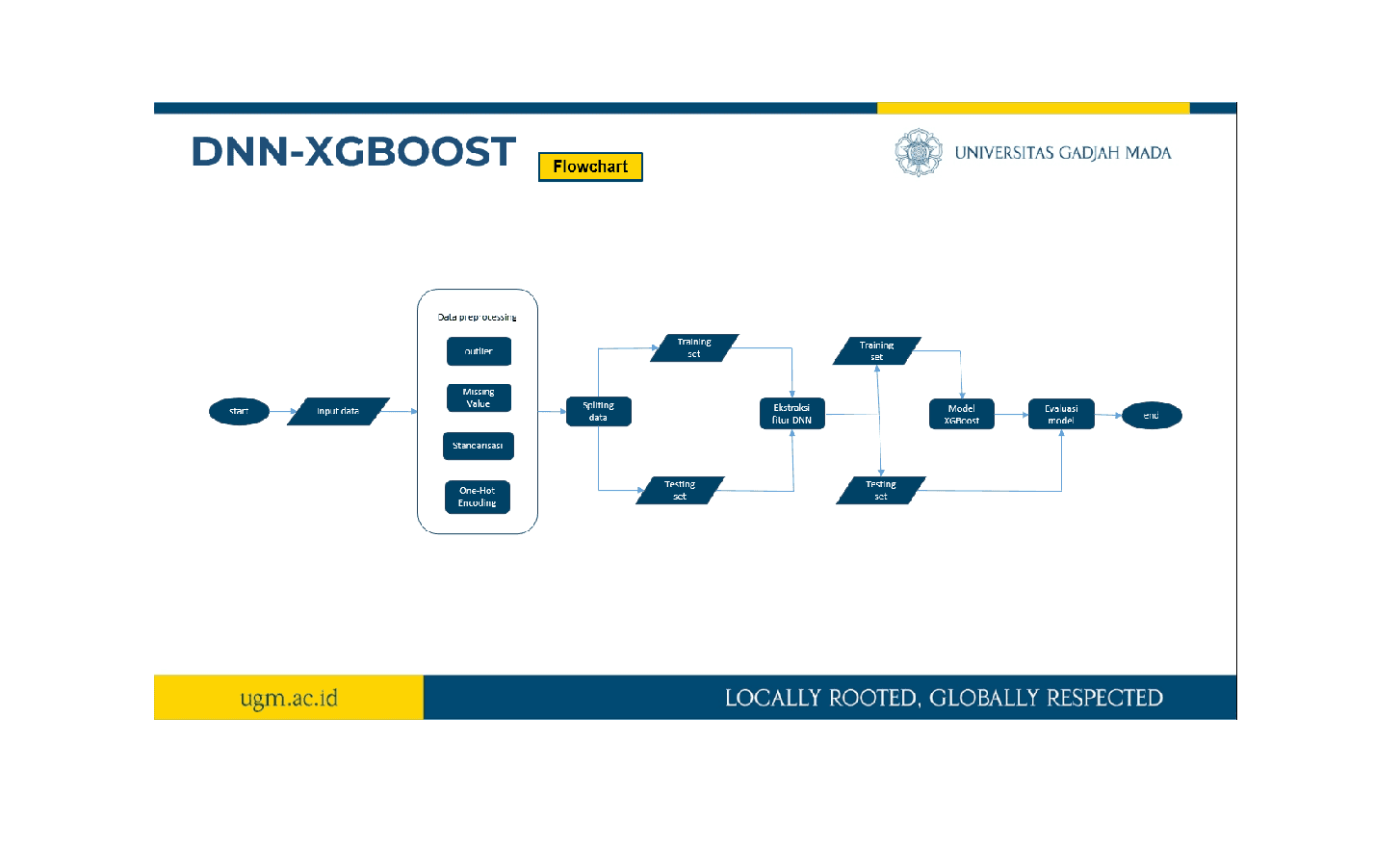
Data Collection & Preprocessing
Selected three benchmark datasets: HMEQ, German, and Japanese Credit Scoring datasets.
Data preprocessing steps included:
Handling outliers and missing values to improve data quality.
Standardization & one-hot encoding to prepare data for machine learning models.
Imbalanced data handling using SMOTE (Synthetic Minority Over-sampling Technique) to balance class distribution.
Split data into training and testing sets to ensure reliable evaluation.
Feature Engineering with DNN
Designed a Deep Neural Network (DNN) for feature extraction:
Activation functions: ReLU for hidden layers, Sigmoid for output.
Optimized using ADAM optimizer for efficient learning.
Extracted feature representations from the last hidden layer before classification.
Classification with XGBoost
Trained an XGBoost classifier using optimized hyperparameters
The hybrid DNN-XGBoost model leverages deep learning’s feature extraction capabilities with XGBoost’s powerful classification performance.
Model Evaluation
Evaluated model performance using confusion matrix & key metrics:
Accuracy, Precision, Recall, F1-Score, Type I error, and Type II error.
Compared the DNN-XGBoost model with single models, including Random Forest, GBM, SVM, Decision Tree, and AdaBoost.
Performance Analysis
The DNN-XGBoost model consistently outperformed traditional machine learning models across all three credit scoring datasets, demonstrating its effectiveness in handling complex feature representations.
📌 HMEQ Dataset – Best Performance
On the HMEQ dataset, the model achieved its highest accuracy of 97.6%, making it the most reliable for credit risk assessment in this dataset. Compared to other models, it excelled in accuracy, precision, and reducing false positives (Type I error). The closest competitors were Random Forest and GBM, while Decision Tree had the weakest performance (67% accuracy).
📌 German Dataset – A Moderate Challenge
The German dataset was more challenging, with the DNN-XGBoost model achieving 76.9% accuracy. While still the best-performing model, the gap between it and other models (like GBM and SVM) was narrower. The Decision Tree struggled the most, with an accuracy of just 57%, proving that simple models fail in complex financial datasets.
📌 Japanese Dataset – Balanced Yet Effective
On the Japanese dataset, DNN-XGBoost remained the top performer (85.7% accuracy), with a notable improvement in recall and F1-score, making it more effective at detecting high-risk borrowers. Interestingly, Random Forest and Decision Tree followed closely, while AdaBoost performed the worst (83% accuracy).
Key Takeaways
DNN-XGBoost consistently outperformed all other models across the three datasets.
It was particularly strong in accuracy, recall, and reducing false positives, making it ideal for credit risk applications.
The model struggled slightly with recall in the HMEQ dataset, indicating a small trade-off in identifying high-risk cases.
Traditional models like Decision Tree and AdaBoost performed poorly, reinforcing the need for advanced feature engineering and boosting techniques.
By leveraging deep learning for feature extraction and XGBoost for classification, this model proved to be a powerful and reliable solution for credit scoring, offering financial institutions a smarter, data-driven approach to risk assessment.